
I am a fourth-year Ph.D. student at University of Chinese Academy of Sciences (UCAS) and Institute of Automation, Chinese Academy of Sciences (CASIA), advisded by Liang Wang.
Previously, I received my B.Eng. degree from Tsinghua University in 2021.
My research focuses on reinforcement learning for enhancing large language models (LLMs), improving their reasoning abilities and making their responses more accurate, reliable, trustworthy, and interpretable. I also study long-term memory for LLMs, aiming to enable LLMs to personalize their behavior through continual interactions with users.
In addition, I work on AI for Drug Discovery (AIDD), developing advanced generative models and algorithms for designing small molecules and proteins.Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Institute of Automation, Chinese Academy of Sciences
Institute of Automation, Chinese Academy of Sciences -
 University of Chinese Academy of SciencesSchool of Artificial Intelligence
University of Chinese Academy of SciencesSchool of Artificial Intelligence
Ph.D. StudentSep. 2021 - present -
 Tsinghua UniversityB.Eng. in Electronic EngineeringSep. 2016 - Jul. 2021
Tsinghua UniversityB.Eng. in Electronic EngineeringSep. 2016 - Jul. 2021
Experience
-
 Xiaohongshu Hi LabRedStar InternAug. 2025 - Present
Xiaohongshu Hi LabRedStar InternAug. 2025 - Present -
 Sea AI LabAssociate MemberJuly. 2025 - Aug. 2025
Sea AI LabAssociate MemberJuly. 2025 - Aug. 2025 -
 ByteDance SeedResearch InternMay. 2025 - Jul. 2025
ByteDance SeedResearch InternMay. 2025 - Jul. 2025 -
ByteDance AI LabResearch InternMay. 2023 - May. 2025
-
ByteDance AMLResearch InternSep. 2022 - May. 2023
Selected Publications (view all )
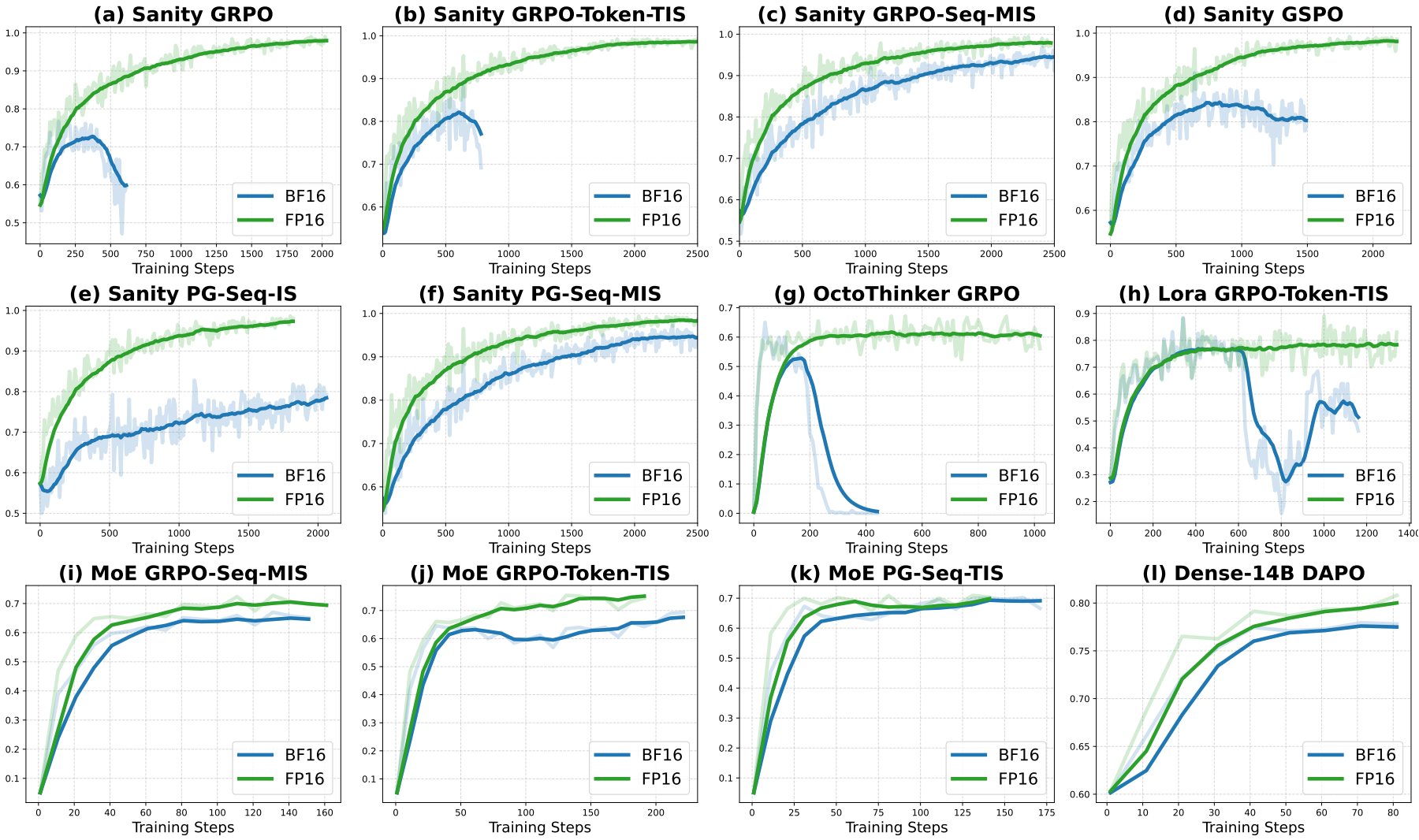
Defeating the Training-Inference Mismatch via FP16
Penghui Qi*, Zichen Liu*, Xiangxin Zhou*, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin (* equal contribution)
Preprint. 2025
We demonstrate that simply reverting to FP16 effectively eliminates the numerical mismatch between the training and inference policies in RL for LLMs. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks.
Defeating the Training-Inference Mismatch via FP16
Penghui Qi*, Zichen Liu*, Xiangxin Zhou*, Tianyu Pang, Chao Du, Wee Sun Lee, Min Lin (* equal contribution)
Preprint. 2025
We demonstrate that simply reverting to FP16 effectively eliminates the numerical mismatch between the training and inference policies in RL for LLMs. Our results suggest that using FP16 uniformly yields more stable optimization, faster convergence, and stronger performance across diverse tasks, algorithms and frameworks.

GEM: A Gym for Agentic LLMs
Zichen Liu*, Anya Sims*, Keyu Duan*, Changyu Chen*, Simon Yu, Xiangxin Zhou, Haotian Xu, Shaopan Xiong, Bo Liu, Chenmien Tan, Chuen Yang Beh, Weixun Wang, Hao Zhu, Weiyan Shi, Diyi Yang, Michael Shieh, Yee Whye Teh, Wee Sun Lee, Min Lin (* equal contribution)
Preprint. 2025
To facilitate this transition we introduce GEM (General Experience Maker), an open-source environment simulator designed for the age of LLMs. Analogous to OpenAI-Gym for traditional reinforcement learning (RL), GEM provides a standardized framework for the environment-agent interface, including asynchronous vectorized execution for high throughput, and flexible wrappers for easy extensibility. GEM also features a diverse suite of environments, robust integrated tools, and single-file example scripts demonstrating using GEM with five popular RL training frameworks.
GEM: A Gym for Agentic LLMs
Zichen Liu*, Anya Sims*, Keyu Duan*, Changyu Chen*, Simon Yu, Xiangxin Zhou, Haotian Xu, Shaopan Xiong, Bo Liu, Chenmien Tan, Chuen Yang Beh, Weixun Wang, Hao Zhu, Weiyan Shi, Diyi Yang, Michael Shieh, Yee Whye Teh, Wee Sun Lee, Min Lin (* equal contribution)
Preprint. 2025
To facilitate this transition we introduce GEM (General Experience Maker), an open-source environment simulator designed for the age of LLMs. Analogous to OpenAI-Gym for traditional reinforcement learning (RL), GEM provides a standardized framework for the environment-agent interface, including asynchronous vectorized execution for high throughput, and flexible wrappers for easy extensibility. GEM also features a diverse suite of environments, robust integrated tools, and single-file example scripts demonstrating using GEM with five popular RL training frameworks.

Variational Reasoning for Language Models
Xiangxin Zhou*, Zichen Liu, Haonan Wang, Chao Du, Min Lin, Chongxuan Li, Liang Wang, Tianyu Pang* (* equal contribution)
Preprint. 2025
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. This framework provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models.
Variational Reasoning for Language Models
Xiangxin Zhou*, Zichen Liu, Haonan Wang, Chao Du, Min Lin, Chongxuan Li, Liang Wang, Tianyu Pang* (* equal contribution)
Preprint. 2025
We introduce a variational reasoning framework for language models that treats thinking traces as latent variables and optimizes them through variational inference. Starting from the evidence lower bound (ELBO), we extend it to a multi-trace objective for tighter bounds and propose a forward-KL formulation that stabilizes the training of the variational posterior. This framework provides a principled probabilistic perspective that unifies variational inference with RL-style methods and yields stable objectives for improving the reasoning ability of language models.
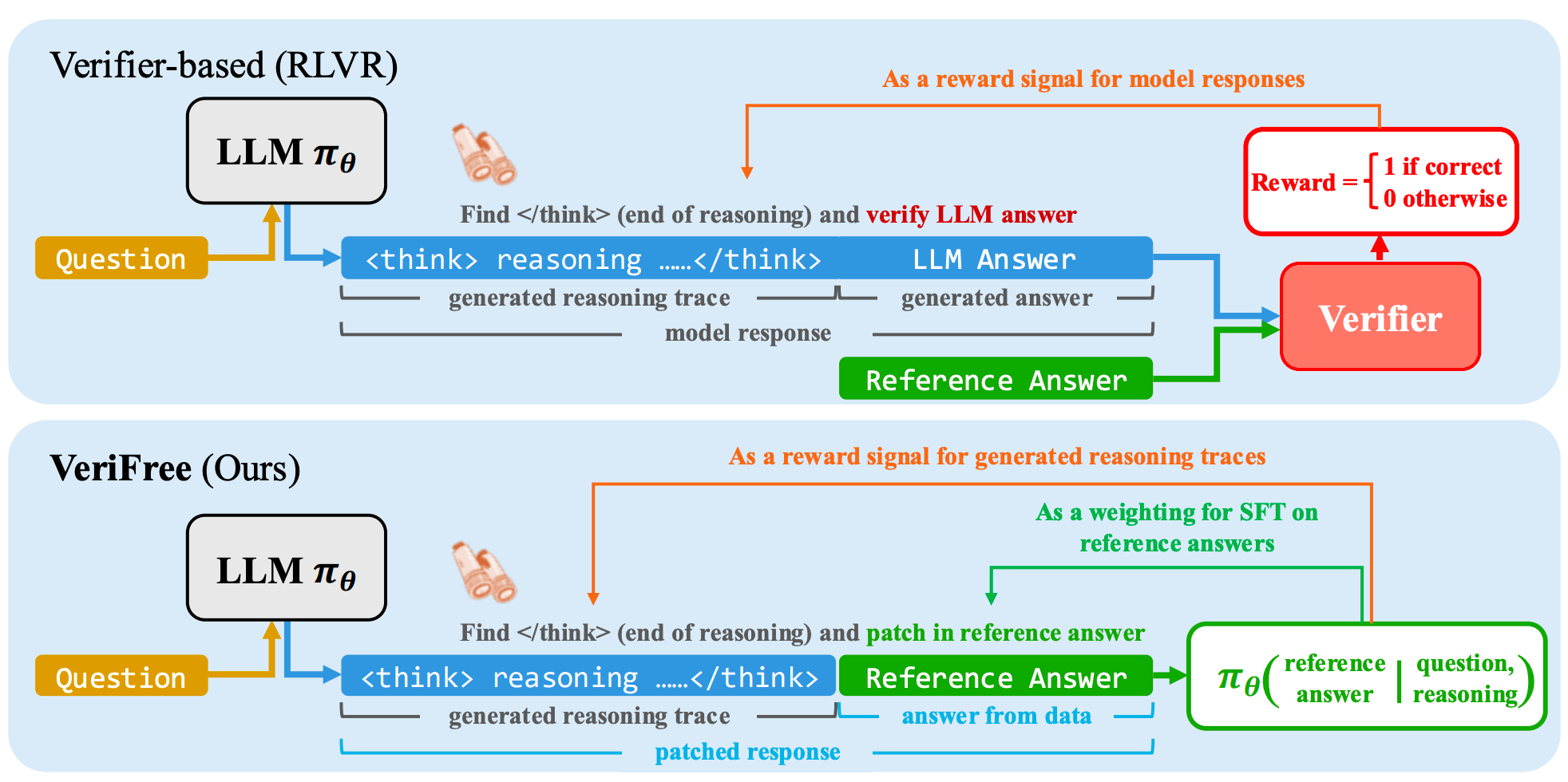
Reinforcing General Reasoning Without Verifiers
Xiangxin Zhou*, Zichen Liu*, Anya Sims*, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, Chao Du (* equal contribution)
Preprint. 2025
VeriFree is a verifier-free method that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer.
Reinforcing General Reasoning Without Verifiers
Xiangxin Zhou*, Zichen Liu*, Anya Sims*, Haonan Wang, Tianyu Pang, Chongxuan Li, Liang Wang, Min Lin, Chao Du (* equal contribution)
Preprint. 2025
VeriFree is a verifier-free method that bypasses answer verification and instead uses RL to directly maximize the probability of generating the reference answer.
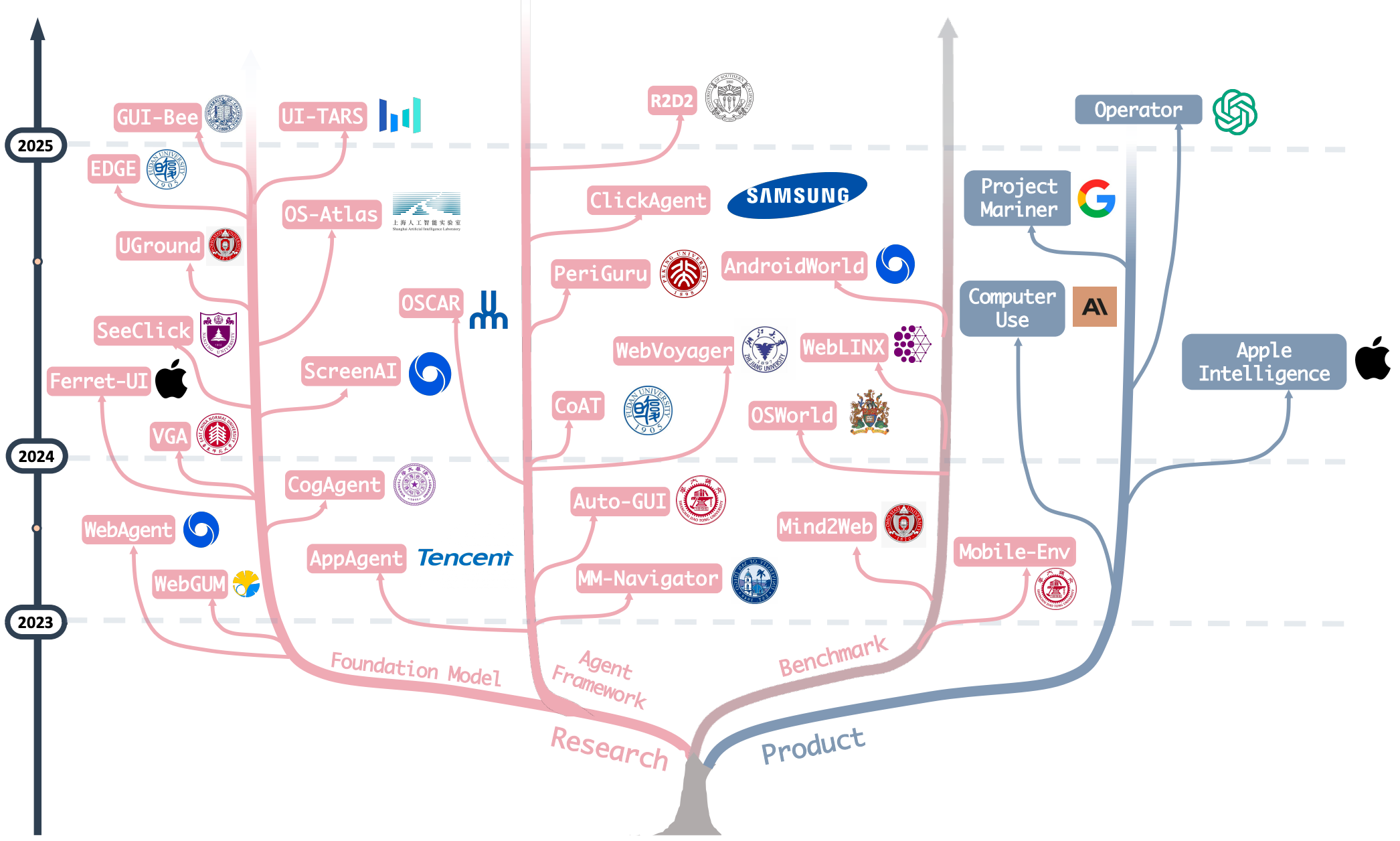
OS Agents: A Survey on MLLM-based Agents for Computer, Phone and Browser Use
Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Ruixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, Yuhuai Li, Shengze Xu, Shawn Wang, Xinchen Xu, Shuofei Qiao, Kun Kuang, Tieyong Zeng, Liang Wang, Jiwei Li, Yuchen Eleanor Jiang, Wangchunshu Zhou, Guoyin Wang, Keting Yin, Zhou Zhao, Hongxia Yang, Fan Wu, Shengyu Zhang, Fei Wu
Annual Meeting of the Association for Computational Linguistics (ACL) 2025 Oral
A comprehensive survey on (M)LLM-based Agents using computers, mobile phones and web browsers by operating within the environments and interfaces (e.g., Graphical User Interface (GUI) and Command Line Interface (CLI)) provided by operating systems (OS) to automate tasks.
OS Agents: A Survey on MLLM-based Agents for Computer, Phone and Browser Use
Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Ruixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, Yuhuai Li, Shengze Xu, Shawn Wang, Xinchen Xu, Shuofei Qiao, Kun Kuang, Tieyong Zeng, Liang Wang, Jiwei Li, Yuchen Eleanor Jiang, Wangchunshu Zhou, Guoyin Wang, Keting Yin, Zhou Zhao, Hongxia Yang, Fan Wu, Shengyu Zhang, Fei Wu
Annual Meeting of the Association for Computational Linguistics (ACL) 2025 Oral
A comprehensive survey on (M)LLM-based Agents using computers, mobile phones and web browsers by operating within the environments and interfaces (e.g., Graphical User Interface (GUI) and Command Line Interface (CLI)) provided by operating systems (OS) to automate tasks.
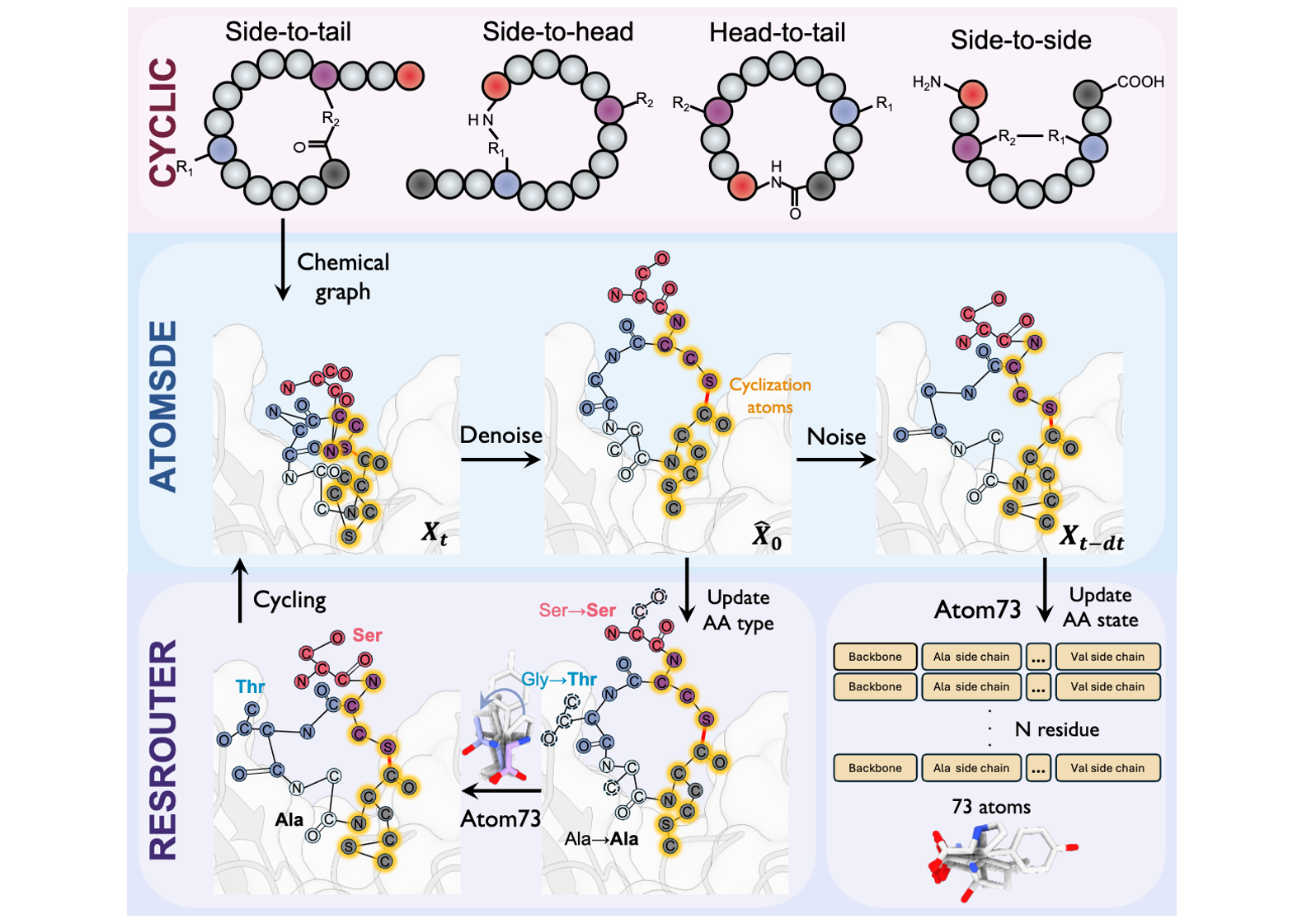
Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
Xiangxin Zhou*, Mingyu Li*, Yi Xiao, Jiahan Li, Dongyu Xue, Zaixiang Zheng, Jianzhu Ma, Quanquan Gu (* equal contribution)
International Conference on Machine Learning (ICML) 2025
CpSDE is a generative algorithm capable of generating diverse types of cyclic peptides given 3D receptor structures.
Designing Cyclic Peptides via Harmonic SDE with Atom-Bond Modeling
Xiangxin Zhou*, Mingyu Li*, Yi Xiao, Jiahan Li, Dongyu Xue, Zaixiang Zheng, Jianzhu Ma, Quanquan Gu (* equal contribution)
International Conference on Machine Learning (ICML) 2025
CpSDE is a generative algorithm capable of generating diverse types of cyclic peptides given 3D receptor structures.
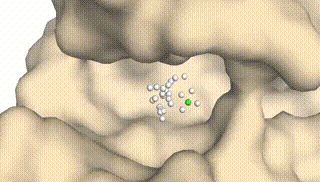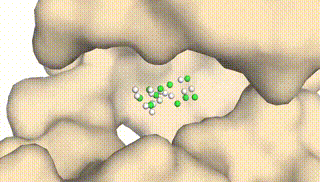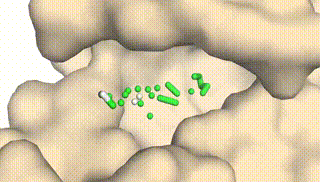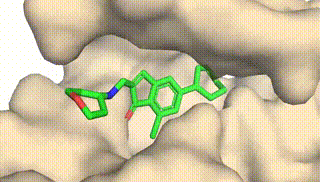
Integrating Protein Dynamics into Structure-Based Drug Design via Full-Atom Stochastic Flows
Xiangxin Zhou*, Yi Xiao*, Haowei Lin, Xinheng He, Jiaqi Guan, Yang Wang, Qiang Liu, Feng Zhou, Liang Wang, Jianzhu Ma (* equal contribution)
International Conference on Learning Representations (ICLR) 2025
DynamicFlow is a full-atom (stochastic) flow model that learns to transform apo pockets and noisy ligands into holo pockets and corresponding 3D ligand molecules.
Integrating Protein Dynamics into Structure-Based Drug Design via Full-Atom Stochastic Flows
Xiangxin Zhou*, Yi Xiao*, Haowei Lin, Xinheng He, Jiaqi Guan, Yang Wang, Qiang Liu, Feng Zhou, Liang Wang, Jianzhu Ma (* equal contribution)
International Conference on Learning Representations (ICLR) 2025
DynamicFlow is a full-atom (stochastic) flow model that learns to transform apo pockets and noisy ligands into holo pockets and corresponding 3D ligand molecules.
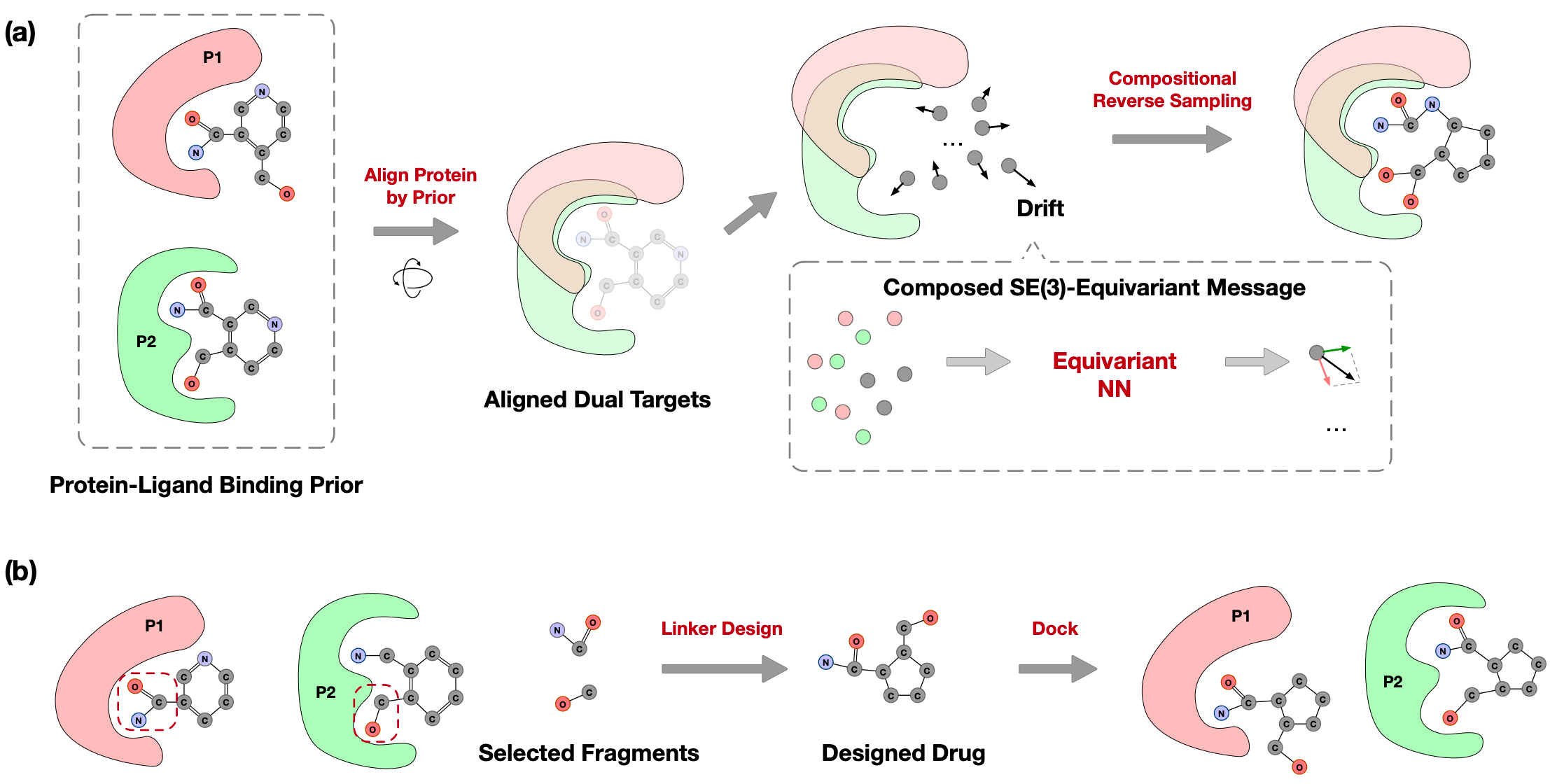
Reprogramming Pretrained Target-Specific Diffusion Models for Dual-Target Drug Design
Xiangxin Zhou, Jiaqi Guan, Yijia Zhang, Xingang Peng, Liang Wang, Jianzhu Ma
Conference on Neural Information Processing Systems (NeurIPS) 2024
DualDiff generates dual-target ligand molecules via compositional sampling based on single-target diffusion models.
Reprogramming Pretrained Target-Specific Diffusion Models for Dual-Target Drug Design
Xiangxin Zhou, Jiaqi Guan, Yijia Zhang, Xingang Peng, Liang Wang, Jianzhu Ma
Conference on Neural Information Processing Systems (NeurIPS) 2024
DualDiff generates dual-target ligand molecules via compositional sampling based on single-target diffusion models.
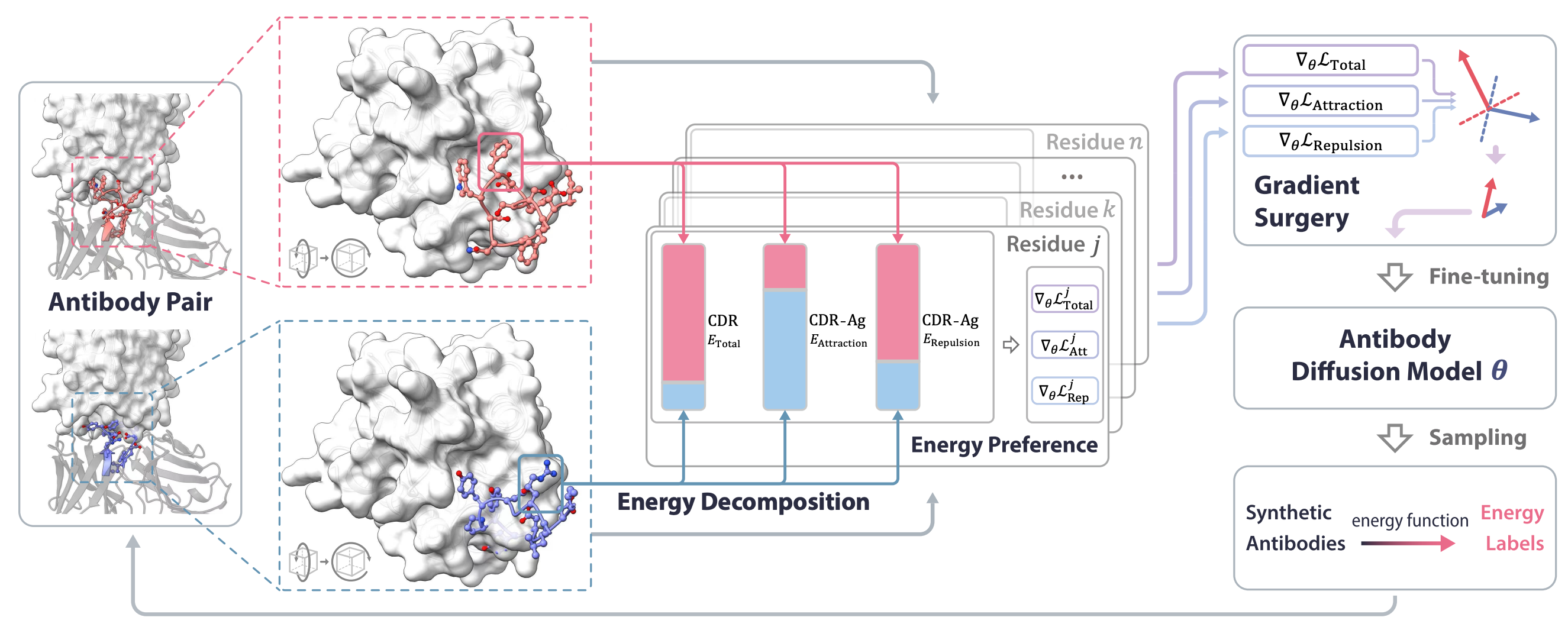
Antigen-Specific Antibody Design via Direct Energy-based Preference Optimization
Xiangxin Zhou*, Dongyu Xue*, Ruizhe Chen*, Zaixiang Zheng, Liang Wang, Quanquan Gu (* equal contribution)
Conference on Neural Information Processing Systems (NeurIPS) 2024
Direct energy-based preference optimzation guides the generation of antibodies with both rational structures and considerable binding affinities to given antigens.
Antigen-Specific Antibody Design via Direct Energy-based Preference Optimization
Xiangxin Zhou*, Dongyu Xue*, Ruizhe Chen*, Zaixiang Zheng, Liang Wang, Quanquan Gu (* equal contribution)
Conference on Neural Information Processing Systems (NeurIPS) 2024
Direct energy-based preference optimzation guides the generation of antibodies with both rational structures and considerable binding affinities to given antigens.
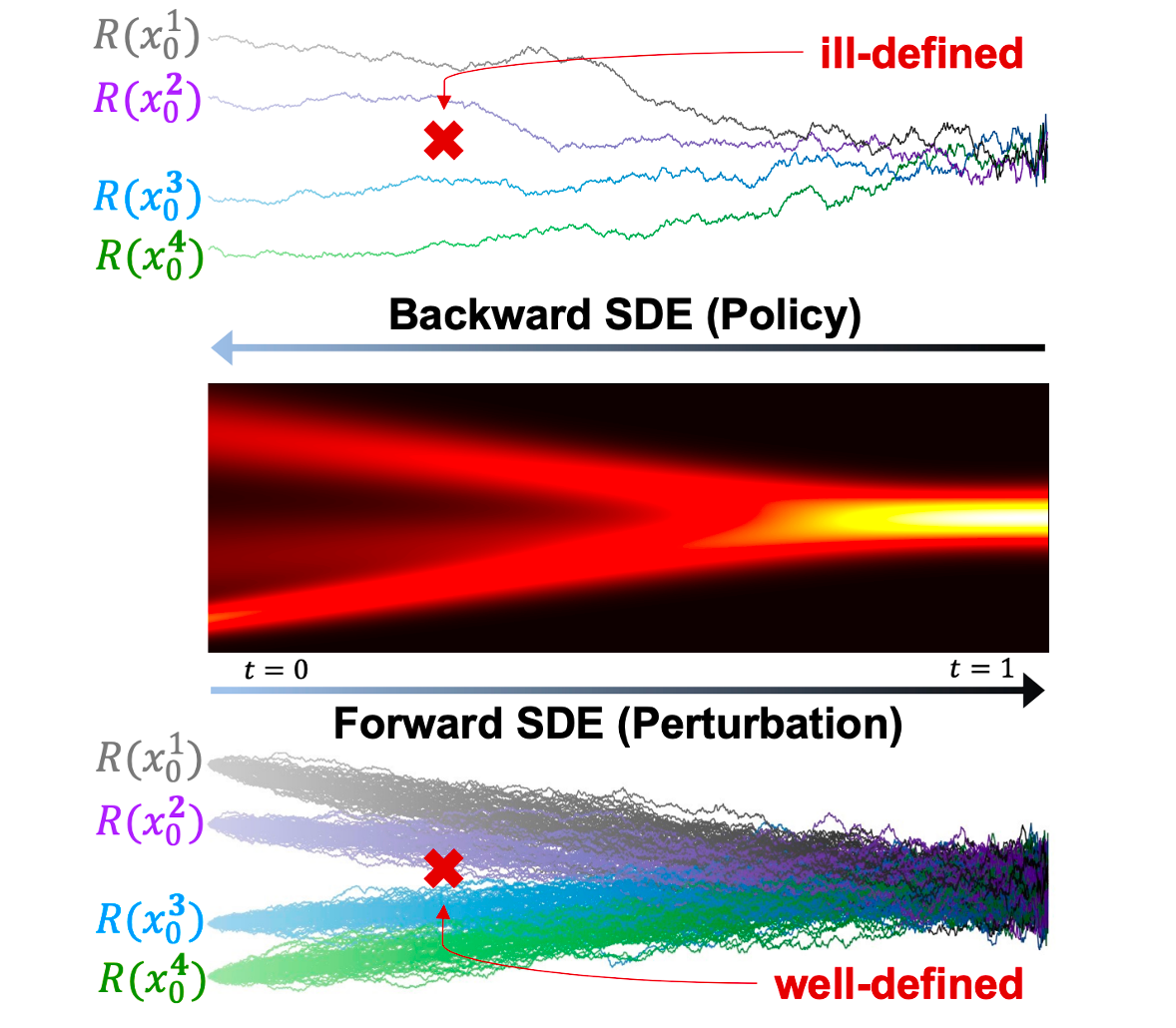
Stabilizing Policy Gradients for Stochastic Differential Equations via Consistency with Perturbation Process
Xiangxin Zhou, Liang Wang, Yichi Zhou
International Conference on Machine Learning (ICML) 2024
Policy gradients in data-scarce regions are ill-defined, leading to instability. Consistency ensured via score matching allows us to correctly estimate the policy gradients with sufficient data that can be efficiently sampled from the forward SDE (i.e., perturbation).
Stabilizing Policy Gradients for Stochastic Differential Equations via Consistency with Perturbation Process
Xiangxin Zhou, Liang Wang, Yichi Zhou
International Conference on Machine Learning (ICML) 2024
Policy gradients in data-scarce regions are ill-defined, leading to instability. Consistency ensured via score matching allows us to correctly estimate the policy gradients with sufficient data that can be efficiently sampled from the forward SDE (i.e., perturbation).
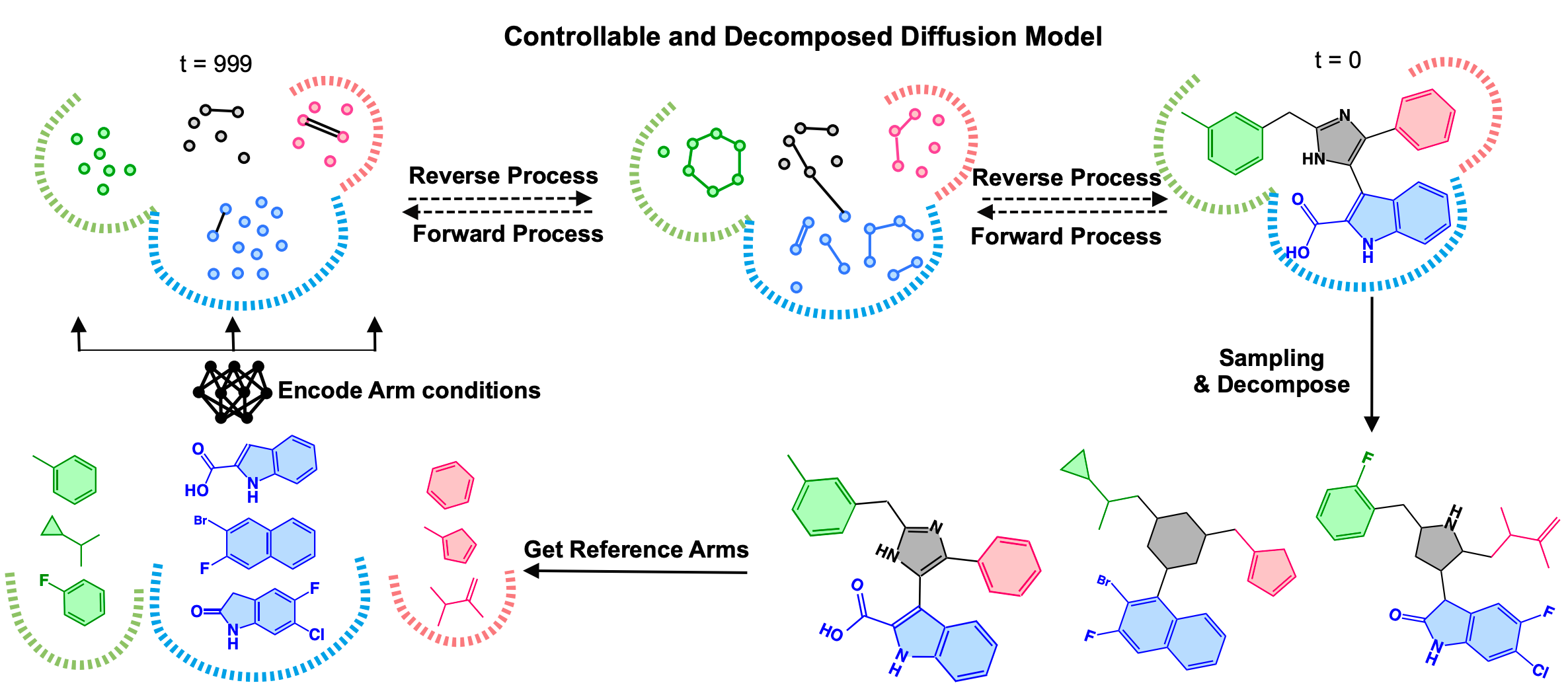
Controllable and Decomposed Diffusion Models for Structure-based Molecular Optimization
Xiangxin Zhou*, Xiwei Cheng*, Yuwei Yang, Yu Bao, Liang Wang, Quanquan Gu (* equal contribution)
International Conference on Learning Representations (ICLR) 2024
DecompOpt a structure-based molecular optimization method based on a controllable and decomposed diffusion model.
Controllable and Decomposed Diffusion Models for Structure-based Molecular Optimization
Xiangxin Zhou*, Xiwei Cheng*, Yuwei Yang, Yu Bao, Liang Wang, Quanquan Gu (* equal contribution)
International Conference on Learning Representations (ICLR) 2024
DecompOpt a structure-based molecular optimization method based on a controllable and decomposed diffusion model.
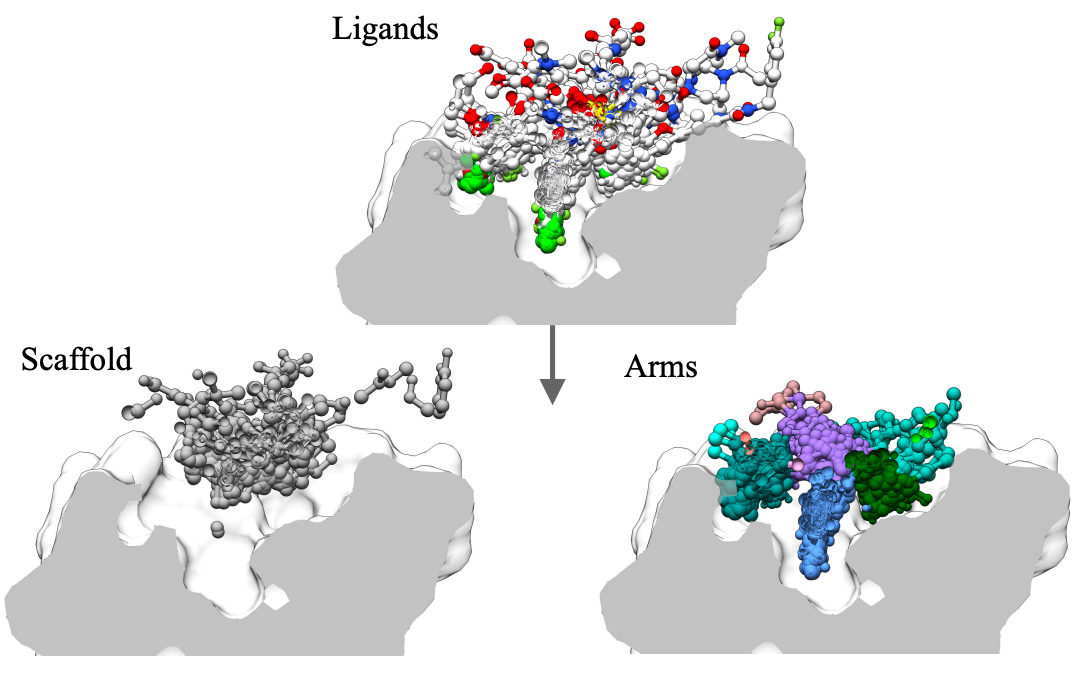
DecompDiff: Diffusion Models with Decomposed Priors for Structure-Based Drug Design
Jiaqi Guan*, Xiangxin Zhou*#, Yuwei Yang, Yu Bao, Jian Peng, Jianzhu Ma, Qiang Liu, Liang Wang, Quanquan Gu# (* equal contribution, # corresponding author)
International Conference on Machine Learning (ICML) 2023
DecompDiff is a diffusion model for SBDD with decomposed priors over arms and scaffold, equipped with bond diffusion and additional validity guidance.
DecompDiff: Diffusion Models with Decomposed Priors for Structure-Based Drug Design
Jiaqi Guan*, Xiangxin Zhou*#, Yuwei Yang, Yu Bao, Jian Peng, Jianzhu Ma, Qiang Liu, Liang Wang, Quanquan Gu# (* equal contribution, # corresponding author)
International Conference on Machine Learning (ICML) 2023
DecompDiff is a diffusion model for SBDD with decomposed priors over arms and scaffold, equipped with bond diffusion and additional validity guidance.